
Not Everything is AI
You don't get to rub some AI on an algo just because it contains an IF statement.

Last week the EU Council proposed several amendments to the April 2022 draft of the Artificial Intelligence Act (AIA), including one that better distinguishes AI from more classical software systems, as the two had previously been conflated. Because the AIA is all about AI, the broad brush with which virtually all algorithmic systems had been painted was obviously problematic. The EU Council states the goal of the proposed amendment:
To ensure that the definition of an AI system provides sufficiently clear criteria for distinguishing AI from simpler software systems, the Council’s text narrows down the definition to systems developed through machine learning approaches and logic- and knowledge-based approaches.
I’m not convinced this definition gets the job done, but regardless, this article is more about the importance of this issue, as conflation of AI with traditional software is shockingly common, even among experts who should know better.
I’ve seen many talks and read countless articles and papers over the years on artificial intelligence … AI regulation, AI and the law, AI policy, AI in society, AI harms, all things AI. I’ve also seen a trend that has existed from the get-go: each and every one of these artifacts seems to contain two key ingredients:
A meticulous definition of AI that goes to great lengths to explain (correctly) that machine learning models are fundamentally different than algorithms created with traditional application programming approaches, followed by …
… an effort to make the concept of AI real with illustrative examples … that inexplicably (and maybe even accidentally) include non-AI, traditional application examples, thus undercutting viewer’s/reader’s ability to discern the two.
This isn’t the most pressing problem in the world, but a rare situation in which the solution is low cost and high benefit for the audiences that will be in a position to act on knowing the difference. Here are some popular non-AI examples that come up repeatedly in AI-centric contexts:
Risk assessment instruments
Risk assessment instruments are used throughout the U.S. court system to support judicial decision making with an increasingly analytical approach that dates back to the 1960’s, as I and many others have written about. The most popular risk assessment instrument on the market, COMPAS, became widely known in 2016 following ProPublica’s exposé of racial bias in the product’s results, which are relied upon for decisions ranging from pretrial detention to sentencing to parole. COMPAS is not AI.
Healthcare risk assessments
Healthcare professionals increasingly rely on software for diagnostic purposes, and in 2019, researchers found that a popular healthcare risk tool on the market, Optum Impact Pro, contained an algorithmic racial bias that was rooted in a key assumption made by its developers, inferred from historical data. Optum Impact Pro is not AI.
Predictive policing
This is a tricky one, because the most popular predictive policing product on the market, PredPol, is indeed enabled by machine learning, but not all law enforcement agencies engaged in this practice use that product or any AI at all. Predictive analytics, absent ML models, have been omnipresent in law enforcement for decades, so use of this scenario to illustrate a harm should be anchored to a real ML model if the purpose is to make AI real.
Who cares?
This goes far beyond a simple annoyance or even a pedantic inclination toward correctness and precision. It’s critical that law and policy students (and practitioners, for that matter) understand this distinction because the appropriate policy response for a particular application of tech in a particular context depends on what constrains it. For example, consider a company’s unwillingness to explain what a system does because it’s proprietary or trade secret, versus an inability to explain what the system does because advanced ML models are notoriously unintelligible. Going further, consider a government agency trying to develop public policy while taking a dependency on this private sector tech. Whether that tech is an unintelligible AI model or an easily explainable, classical software application will have a nontrivial impact on the policy.
This distinction also relates to litigation over the role of algorithmic systems in consequential decision making. In the tech policy and ethics community, State v. Loomis is a well-known Wisconsin case in which a convicted offender claimed his due process rights were violated because he didn’t have visibility into the COMPAS risk instrument that the sentencing judge was using to assess his likelihood of reoffending upon release. The outcome of the case is less important than the question before the court: was Eric Loomis constitutionally entitled to know how a computer program produced the high risk scores upon which the judge relied (even if only partially) to determine his sentence? If COMPAS were a deep learning model, the question of “how” would be unresolvable, as even its developers wouldn’t be able to explain what it’s doing. But COMPAS is a traditional application software program, and its creator’s resistance to providing transparency was (and remains) rooted in protection of trade secrecy, as the tool’s underlying algorithms are proprietary.
What should be the policy response to widespread use of COMPAS in the courts? Well, if it were a sophisticated deep learning model with zero intelligibility, then we’d have to rely on periodic independent audits for detection of bias and enforcement of mitigations, as even deep learning’s creators can’t explain exactly what these models do. Even then, it’s hard to argue a defendant received the benefit of due process rights at the hands of a tool that is an unexplainable black box. But COMPAS is not a deep learning model, so we have more options, including a regulatory regime that requires algorithmic transparency into the execution of calculations that produce consequential outputs.
Simple Tools
How should we approach this to make it easy to understand for as broad an audience as possible? To make things simple, here’s a graphic I use in class to describe what AI is:

And to illustrate the importance of not conflating AI with traditional apps, here’s a slide I used last year to discuss the AIA’s broad Annex I definition in the initial version, which this November set of amendments (partially) addresses:

While machine learning uses “statistical approaches”, there are plenty of statistical methods also at play in the development of human-authored rules that developers codify in traditional apps. And finally, here’s how I spend at least two lectures making sure students understand what they’re dealing with when called upon to conduct a tech policy analysis or develop a policy response to a tech implementation, courtesy of data science consultancy Datalya, which published a short blog about this in 2020:

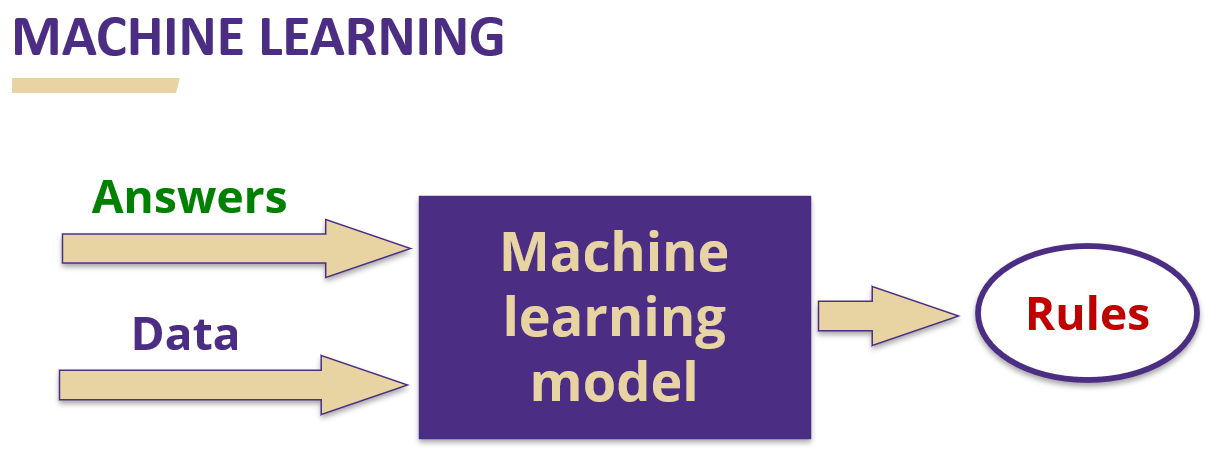
While this is not perfect, this delineation is nonetheless helpful in describing (mostly for non-technical folks) that application developers create programmatic rules through which to pass data and generate answers, while ML practitioners use existing data (“answers”) to generate models that make forward-looking predictions (“rules”) about new inputs (“data”). Sometimes traditional applications are re-engineered as ML models because they perform better, as is the case in this example:

Needless to say, machine learning involves a fraction of the code because there’s no need for a developer to write each and every programmatic rule for execution by the app. If (hypothetically) each of these two machine-translation methods were the subject of a policy or regulatory regime that endeavored to create transparency, the approach for each would be quite a bit different.
Getting “AI” into the title of a talk or a paper or a course listing is generally rewarded with more attention than simply saying “algorithms” or the more accurate “algorithmic decision systems”, and we’ve all done it. But if the artifact is broader than just AI, we make a Faustian bargain: we get the engagement but we also risk misinforming the very people we’re trying to empower with learning. These same people, in the absence of any corrective clarity, will end up in policymaking roles thinking that any system with an IF_THEN_ELSE statement is a machine learning model. That is unhelpful in a world in which the lack of tech literacy in government is partially to blame for the yawning gap between the advancement of modern technology and the glacial pace of law- and policymaking. We should not unrealistically aspire to transform law- and policymakers into computer scientists, but there are some basic, explain-it-like-I’m-a-first-grader tools we can use to bridge knowledge gaps and mitigate the potential for perceived tech complexity to undercut well-intentioned efforts to ensure safeguards. At some point in the future, the accessibility of machine learning to a broader set of practitioners might put legacy systems into steep decline, but between now and then, we need to apply some intellectual honesty to what’s in use today, and what these systems are & are not.
/end